
Semantic Indexing of animal experiments summaries
This task will continue to explore the automatic assignment of ICD-10 codes to health-related documents with the focus on the German language and on non-technical summaries (NTPs) of animal experiments.
In 2019, participants will be challenged with the semantic indexing of NTPs using codes from the German version of the International Classification of Diseases (ICD-10). The NTPs are short summaries which are currently publicly available in the AnimalTestInfo database, as part of the approval procedure for animal experiments in Germany. The database currently contains more than 10,000 NTPs,many of which have been manually indexed by experts, and that will be used as training data.
Only fully automated approaches will be allowed.
Timeline
- Training set release: 24 January 2019
- Test set release: May 6th 2019
- Result submission: May 13th 2019
- Participants’ working notes papers submitted [CEUR-WS]: check Important Dates page
- Notification of Acceptance Participant Papers [CEUR-WS]: check Important Dates page
- Camera Ready Copy of Participant Papers [CEUR-WS] due: check Important Dates page
- CLEFeHealth2019 one-day lab session: check Important Dates page
Targeted Participants
The task is open for everybody. We particularly welcome academic and industrial researchers, scientists, engineers and graduate students in natural language processing, machine learning and biomedical/health informatics to participate. We also encourage participation by multi-disciplinary teams that combine technological skills with biomedical expertise.
Training Data
The training data is available here.
The above zip file includes the documents, annotations and a README file with details on the data.
Please notice that our annotations are based on the ICD-10 German Modification 2016 version.
Test Set and Submission Guidelines
The test set is available here.
The format of the documents in the test set will the same as the documents in the training data folder (docs-training/), i.e. one file for document in plain text format.
The format for the submission file will be the same as the annotations file (anns_train_dev.txt) in the training data, as illustrated in the example below:
17288 J95-J99|X
4970 C50-C50|C00-C97|C00-C75|II
…
Each line contains the document identifier, separated by a TAB symbol, to the list of one or mode ICD-10 codes. Codes should be separated by a pipe symbol (|). The document identifiers are the ones to be released in the test set as identified by their file name.
All codes should be chapters or groups from the ICD-10 German Modification 2016 version.
Submission files should be uploaded to our EasyChair submission site. Please select the option “MultiIETask 1: Indexing of Animal Experiments” in the “Topics” section.
Each team is allowed to submit up to three runs.
Evaluation Methods
We will evaluate the predictions based on the usual metrics of Precision, Recall and F-Score.
We released an evaluation script for the development set.
Results for the test set
The scores were calculated using the above Python script. The teams and corresponding results are presented in alphabetical order.
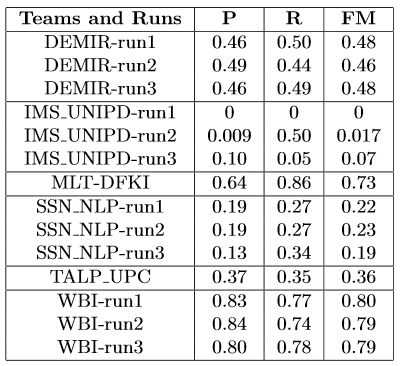
Regarding the runs from team IMS_UNIPD, run1, run2 and run3 are the ones identified by the participants as Bernoulli, Multinomial and Poisson, respectively.
Registration
Please register on the main CLEF 2019 registration page at http://clef2019-labs-registration.dei.unipd.it/
Further Information
AnimalTestInfo database: http://www.animaltestinfo.de
Bert B, Dörendahl A, Leich N, Vietze J, Steinfath M, et al. (2017) Rethinking 3R strategies: Digging deeper into AnimalTestInfo promotes transparency in in vivo biomedical research. PLOS Biology 15(12): e2003217. https://doi.org/10.1371/journal.pbio.2003217